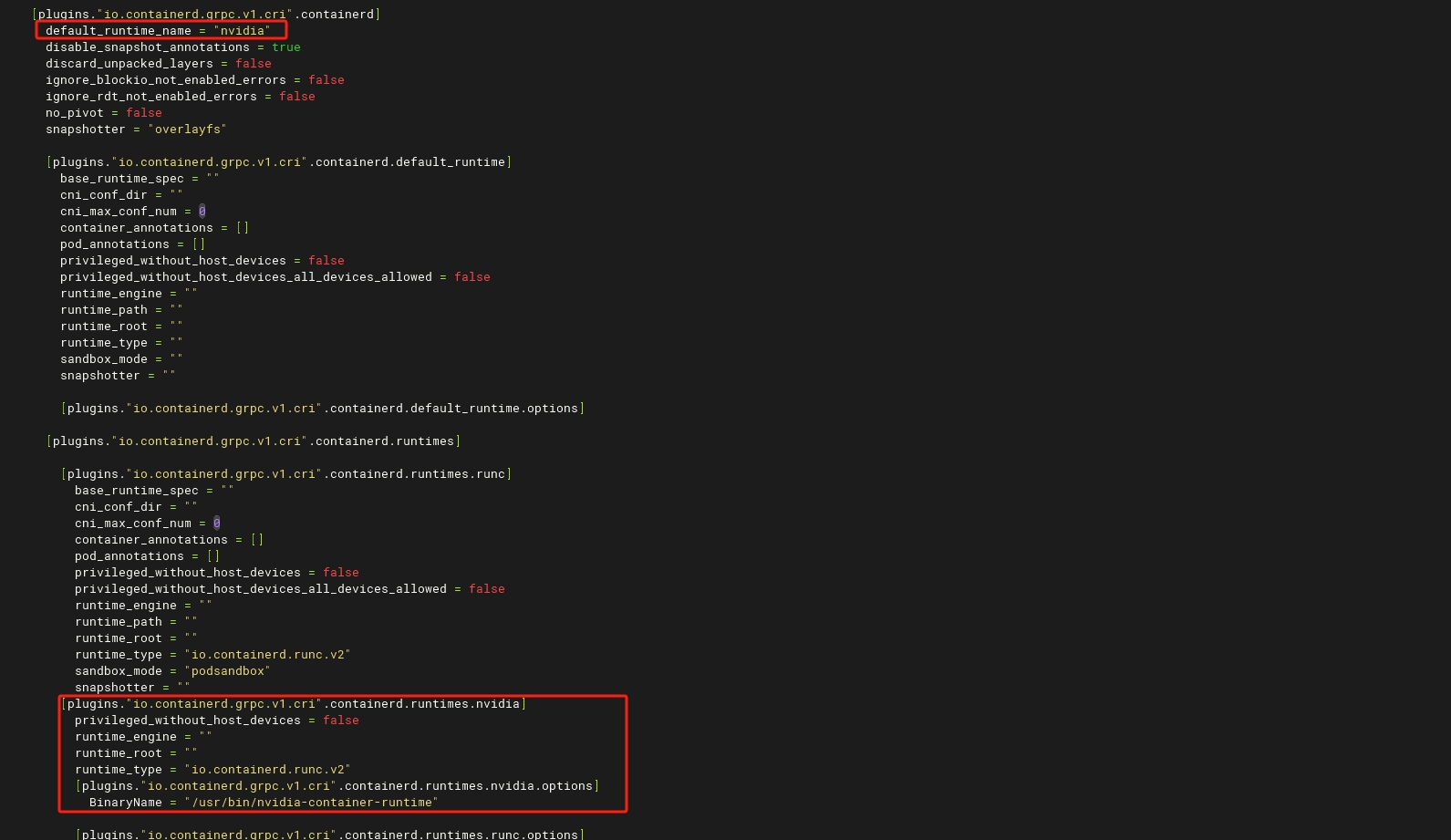
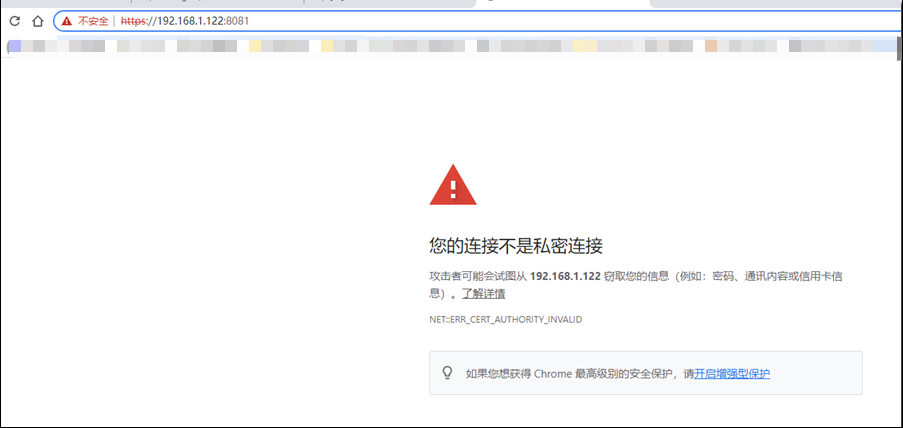
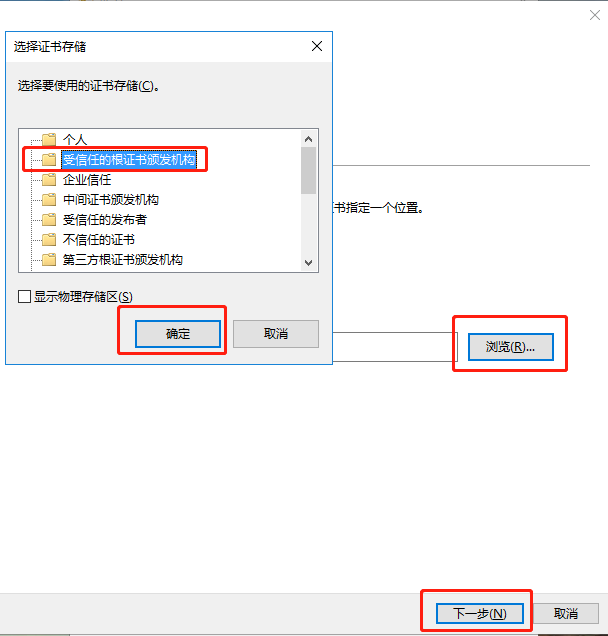
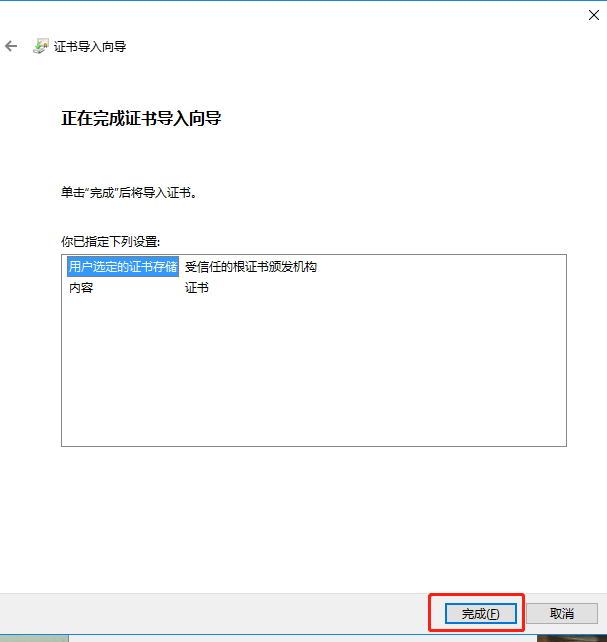
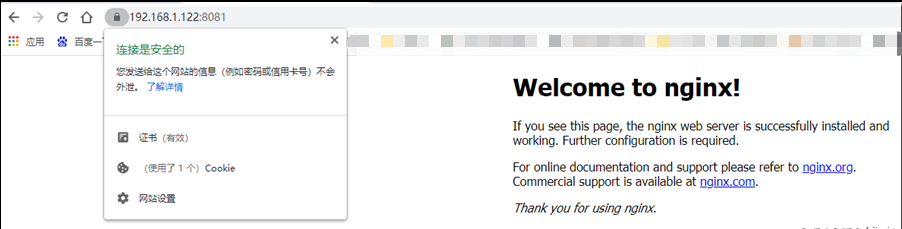
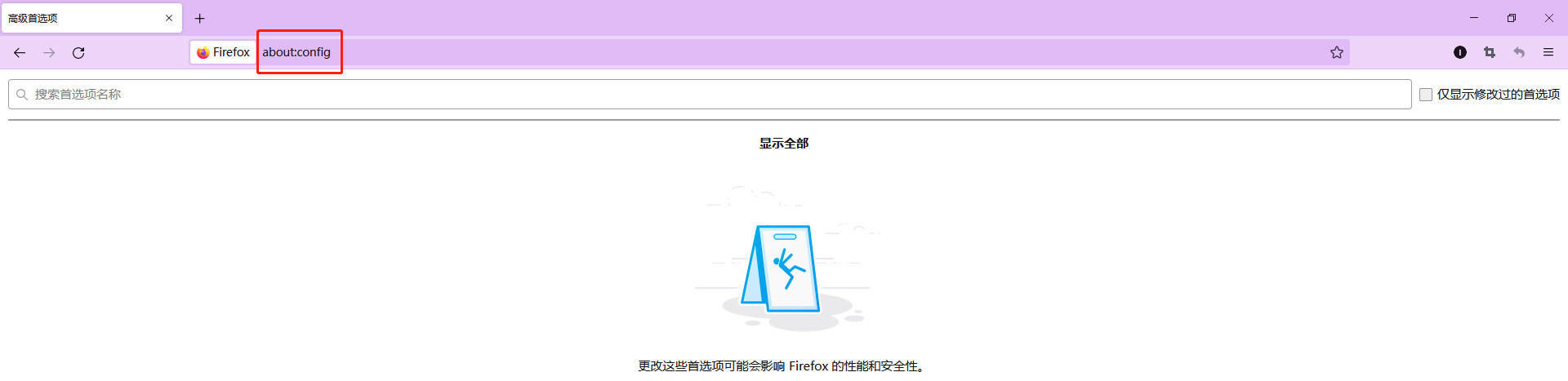
$ kubectl logs gpu-pod [Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
funcNewRequest(method, url string, body io.Reader)(*Request, error) { if method == "" { // We document that "" means "GET" for Request.Method, and people have // relied on that from NewRequest, so keep that working. // We still enforce validMethod for non-empty methods. method = "GET" } if !validMethod(method) { returnnil, fmt.Errorf("net/http: invalid method %q", method) } u, err := parseURL(url) // Just url.Parse (url is shadowed for godoc). if err != nil { returnnil, err } rc, ok := body.(io.ReadCloser) if !ok && body != nil { rc = ioutil.NopCloser(body) } // The host's colon:port should be normalized. See Issue 14836. u.Host = removeEmptyPort(u.Host) req := &Request{ Method: method, URL: u, Proto: "HTTP/1.1", ProtoMajor: 1, ProtoMinor: 1, Header: make(Header), Body: rc, Host: u.Host, } if body != nil { switch v := body.(type) { case *bytes.Buffer: req.ContentLength = int64(v.Len()) buf := v.Bytes() req.GetBody = func()(io.ReadCloser, error) { r := bytes.NewReader(buf) return ioutil.NopCloser(r), nil } case *bytes.Reader: req.ContentLength = int64(v.Len()) snapshot := *v req.GetBody = func()(io.ReadCloser, error) { r := snapshot return ioutil.NopCloser(&r), nil } case *strings.Reader: req.ContentLength = int64(v.Len()) snapshot := *v req.GetBody = func()(io.ReadCloser, error) { r := snapshot return ioutil.NopCloser(&r), nil } default: // This is where we'd set it to -1 (at least // if body != NoBody) to mean unknown, but // that broke people during the Go 1.8 testing // period. People depend on it being 0 I // guess. Maybe retry later. See Issue 18117. } // For client requests, Request.ContentLength of 0 // means either actually 0, or unknown. The only way // to explicitly say that the ContentLength is zero is // to set the Body to nil. But turns out too much code // depends on NewRequest returning a non-nil Body, // so we use a well-known ReadCloser variable instead // and have the http package also treat that sentinel // variable to mean explicitly zero. if req.GetBody != nil && req.ContentLength == 0 { req.Body = NoBody req.GetBody = func()(io.ReadCloser, error) { return NoBody, nil } } }
Error: Could not find expected file libmongoc-1.0/mongoc.h, or libmongoc-1.0/mongoc.h for LIBMONGOC – you may have to install LIBMONGOC in your system and/or pass LIBMONGOC_DIR or LIBMONGOC_INCDIR to the luarocks command. Example: luarocks install mongorover LIBMONGOC_DIR=/usr/local
三、安装cmake
因为mongo-c-driver需要使用cmake进行编译
1 2 3 4 5 6 7
yum install gcc gcc-c++ ncurses-devel wget wget https://cmake.org/files/v3.3/cmake-3.3.2.tar.gz tar -xzf cmake-3.3.2.tar.gz cd cmake-3.3.2/ ./bootstrap gmake gmake install
wget https://github.com/mongodb/mongo-c-driver/releases/download/1.17.6/mongo-c-driver-1.17.6.tar.gz tar -xzf mongo-c-driver-1.17.6.tar.gz cd mongo-c-driver-1.17.6/ cmake . make make install
wget https://github.com/openresty/lua-resty-core/archive/v0.1.21.tar.gz tar -zxvf lua-resty-core-0.1.21.tar.gz cd lua-resty-core-0.1.21 make install
3、安装lua-resty-lrucache
1 2 3 4
wget https://github.com/openresty/lua-resty-lrucache/archive/v0.10.tar.gz tar -zxvf lua-resty-lrucache-0.10.tar.gz cd lua-resty-lrucache-0.10 make install
4、解压lua-nginx-module
1 2
wget https://github.com/openresty/lua-nginx-module/archive/v0.10.19.tar.gz tar -zxvf lua-nginx-module-0.10.19.tar.gz
5、解压ngx_devel_kit
1 2
wget https://github.com/vision5/ngx_devel_kit/archive/v0.3.1.tar.gz tar -zxvf ngx_devel_kit-0.3.1.tar.gz
6、解压openssl
1 2
wget https://www.openssl.org/source/openssl-1.1.1k.tar.gz tar -zxvf openssl-1.1.1k.tar.gz